



LLM-as-a-Judge in Evaluation-Centric AI: Trends and Challenges
- Authors
-
-
Author
-
Author
-
- Keywords:
- Large Language Models (LLMs), LLM-as-a-judge, Benchmarking, Evaluation of Language Models, Retrieval-Augmented Generation (RAG), AI Robustness, Low-Resource Languages, Automated Annotation, AI Deployment, Natural Language Processing (NLP)
- Abstract
-
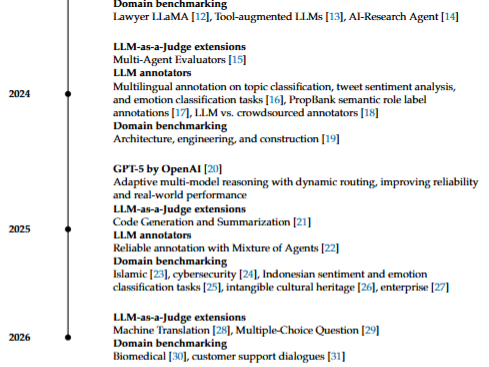
Large Language Models (LLMs) have undergone a rapid transformation from architectural innovations to widely deployed intelligent systems. This editorial traces the evolution of LLMs through a structured timeline, beginning with the introduction of the Transformer architecture, which enabled scalable attention-based learning across diverse language tasks. This foundation was extended through generative pre-training paradigms, leading to increasingly capable models such as GPT-3, which demonstrated few-shot learning at scale. Subsequent developments addressed key limitations of parametric models, particularly their static knowledge boundaries, through the introduction of Retrieval-Augmented Generation (RAG), enabling dynamic integration of external information during inference. The emergence of instruction tuning and reinforcement learning from human feedback further enabled alignment with human intent, culminating in the deployment of conversational systems such as ChatGPT. More recently, the field has entered a new phase characterized by the rise of open-weight LLM ecosystems and evaluation-centric methodologies. In particular, the introduction of LLM-as-a-judge has redefined evaluation by enabling scalable, model-based assessment of generated outputs, while LLM-based annotation and multi-agent evaluation frameworks have further expanded the role of LLMs from generators to evaluators. This progression reflects a fundamental shift in LLM research, from model-centric development toward evaluation, benchmarking, robustness, and real-world deployment. Despite this shift, existing publication venues remain largely focused on model design, leaving a gap for evaluation-driven research. To address this need, we introduce Artificial Intelligence and Language Models (AILM), an open-access journal dedicated to advancing research on LLM evaluation, benchmarking, LLM-as-a-judge frameworks, retrieval-augmented systems, and low-resource language applications. AILM aims to provide a platform for the next phase of AI research, where reliability, reproducibility, and real-world impact are central concerns.
- Downloads
-
Download data is not yet available.
- References
-
Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30, pp. 5998–6008. https://doi.org/10.5555/3295222.3295349
Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. Technical Report, 2018.
Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I.; et al. Language Models Are Unsupervised Multitask Learners. Technical Report, 2019.
Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems; 2020; Volume 33, pp. 1877–1901. https://doi.org/10.5555/3495724.3495883
Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.-t.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc., 2020; Volume 33, pp. 9459–9474.
Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.L.; Mishkin, P.; Zhang, C.; Agarwal, S.; et al. Training Language Models to Follow Instructions with Human Feedback. In Proceedings of the Advances in Neural Information Processing Systems; 2022; Volume 35.
OpenAI. Introducing ChatGPT. OpenAI Blog, 2022.
Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774.
Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971.
Bai, J.; Bai, S.; Chu, Y.; Cui, Z.; Dang, K.; Deng, X.; Fan, Y.; Ge, W.; Han, Y.; Huang, F.; et al. Qwen Technical Report. arXiv 2023, arXiv:2309.16609.
Zheng, L.; Chiang, W.L.; Sheng, Y.; Zhuang, S.; Wu, Z.; Zhuang, Y.; Lin, Z.; Li, Z.; Li, D.; Xing, E.; et al. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. Adv. Neural Inf. Process. Syst. 2023, 36, 46595–46623.
Huang, Q.; Tao, M.; Zhang, C.; An, Z.; Jiang, C.; Chen, Z.; Wu, Z.; Feng, Y. Lawyer LLaMA Technical Report. arXiv 2023, arXiv:2305.15062.
Li, M.; Zhao, Y.; Yu, B.; Song, F.; Li, H.; Yu, H.; Li, Z.; Huang, F.; Li, Y. API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Singapore, 2023; pp. 3102–3116. https://doi.org/10.18653/v1/2023.emnlp-main.187
Huang, Q.; Vora, J.; Liang, P.; Leskovec, J. Benchmarking Large Language Models as AI Research Agents. In Proceedings of the NeurIPS 2023 Workshop on Foundation Models for Decision Making; 2023.
Chan, C.M.; Chen, W.; Su, Y.; Yu, J.; Xue, W.; Zhang, S.; Fu, J.; Liu, Z. ChatEval: Towards Better LLM-Based Evaluators through Multi-Agent Debate. arXiv 2023, arXiv:2308.07201.
Nasution, A.H.; Onan, A. ChatGPT Label: Comparing the Quality of Human-Generated and LLM-Generated Annotations in Low-Resource NLP Tasks. IEEE Access 2024, 12, 71876–71900. https://doi.org/10.1109/ACCESS.2024.3402809
Bonn, J.; Madabushi, H.T.; Hwang, J.D.; Bonial, C. Adjudicating LLMs as PropBank Annotators. In Proceedings of the Conference on Computational Linguistics; 2024; pp. 112–123.
He, X.; Lin, Z.; Gong, Y.; Jin, A.L.; Zhang, H.; Lin, C.; Jiao, J.; Yiu, S.M.; Duan, N.; Chen, W. AnnoLLM: Making Large Language Models Better Crowdsourced Annotators. In Proceedings of NAACL Industry Track; 2024; pp. 165–190. https://doi.org/10.18653/v1/2024.naacl-industry.15
Liang, C.; Yan, S.; Guo, Q.; Sun, J.; Cheng, F.; Liu, Z.; Xiao, W.; Wang, M.; Wang, H.; Zhao, X. AEC-Bench: A Multidisciplinary Multilevel Chinese Evaluation Benchmark for Large Language Models in AEC. In Proceedings of the ASCE Conference; 2024; pp. 137–146. https://doi.org/10.1061/9780784486115.014
Singh, A.; Fry, A.; Perelman, A.; Tart, A.; Ganesh, A.; El-Kishky, A.; McLaughlin, A.; Low, A.; Ostrow, A.; Ananthram, A.; et al. OpenAI GPT-5 System Card. arXiv 2025, arXiv:2601.03267.
Crupi, G.; Tufano, R.; Velasco, A.; Mastropaolo, A.; Poshyvanyk, D.; Bavota, G. On the Effectiveness of LLM-as-a-Judge for Code Generation and Summarization. IEEE Trans. Softw. Eng. 2025, 51, 2329–2345. https://doi.org/10.1109/TSE.2025.3586082
Onan, A.; Nasution, A.H.; Celikten, T. Toward Reliable Annotation in Low-Resource NLP: A Mixture of Agents Framework and Multi-LLM Benchmarking. IEEE Access 2025, 13, 211620–211644.
Khalila, Z.; Nasution, A.H.; Monika, W.; Onan, A.; Murakami, Y.; Radi, Y.B.I.; Osmani, N.M. Investigating Retrieval-Augmented Generation in Quranic Studies: A Study of 13 Open-Source Large Language Models. Int. J. Adv. Comput. Sci. Appl. 2025, 16, 1361–1371. https://doi.org/10.14569/IJACSA.2025.01602134
Nasution, A.H.; Monika, W.; Onan, A.; Murakami, Y. Benchmarking 21 Open-Source Large Language Models for Phishing Link Detection with Prompt Engineering. Information 2025, 16, 366. https://doi.org/10.3390/info16050366
Nasution, A.H.; Onan, A.; Murakami, Y.; Monika, W.; Hanafiah, A. Benchmarking Open-Source Large Language Models for Sentiment and Emotion Classification in Indonesian Tweets. IEEE Access 2025, 13, 94009–94025. https://doi.org/10.1109/ACCESS.2025.3574629
Zhao, Z.; Wang, D. Evaluation of Large Language Models for the Intangible Cultural Heritage Domain. npj Herit. Sci. 2025, 13. https://doi.org/10.1038/s40494-025-02013-1
Zhang, B.; Takeuchi, M.; Kawahara, R.; Asthana, S.; Hossain, M.M.; Ren, G.J.; Soule, K.; Mai, Y.; Zhu, Y. Evaluating Large Language Models with Enterprise Benchmarks. In Proceedings of NAACL Industry Track; 2025; pp. 485–505. https://doi.org/10.18653/v1/2025.naacl-industry.40
Shalawati, S.; Nasution, A.H.; Monika, W.; Derin, T.; Onan, A.; Murakami, Y. Beyond BLEU: GPT-5, Human Judgment, and Classroom Validation for Multidimensional Machine Translation Evaluation. Digital 2026, 6, 8. https://doi.org/10.3390/digital6010008
Onan, A.; Nasution, A.H.; Celikten, T.; Cetin, P. Comparing ChatGPT, Gemini, and Emerging LLMs in Low-Resource Educational Settings: Reasoning Quality, Consistency, and Explainability. IEEE Access 2026, 14, 32807–32838. https://doi.org/10.1109/ACCESS.2026.3669036
Zhu, J.; Li, J.; Zhao, S.; Deng, Y.; Miao, Y.; Xu, J. Adapting LLMs for Biomedical Natural Language Processing: A Comprehensive Benchmark Study on Fine-Tuning Methods. J. Supercomput. 2026, 82. https://doi.org/10.1007/s11227-025-08182-x
Karpov, I.; Kirillovich, A.; Goncharova, E.; Parinov, A.; Chernyavskiy, A.; Ilvovsky, D.; Semenova, N.; Sosedka, A.; Lisitsyna, E.; Belkin, M. SynEL: A Synthetic Benchmark for Entity Linking. PLoS ONE 2026, 21. https://doi.org/10.1371/journal.pone.0339468
Karpukhin, V.; Oguz, B.; Min, S.; Lewis, P.; Wu, L.; Edunov, S.; Chen, D.; Yih, W.-t. Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics: 2020; pp. 6769–6781. https://doi.org/10.18653/v1/2020.emnlp-main.550
Huang, L.; Yu, W.; Ma, W.; Zhong, W.; Feng, Z.; Wang, H.; Chen, Q.; Peng, W.; Feng, X.; Qin, B.; et al. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. ACM Comput. Surv. 2025. https://doi.org/10.1145/3703155
Snow, R.; O’Connor, B.; Jurafsky, D.; Ng, A. Cheap and Fast—But Is It Good? Evaluating Non-Expert Annotations for Natural Language Tasks. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: 2008; pp. 254–263.
Liu, Y.; Iter, D.; Xu, Y.; Wang, S.; Xu, R.; Zhu, C. G-Eval: NLG Evaluation Using GPT-4 with Better Human Alignment. In Proceedings of EMNLP 2023; 2023. https://doi.org/10.18653/v1/2023.emnlp-main.153
Alabdulwahab, A.; Japic, C.; Le, C.; et al. Comparative Study of Large Language Model Evaluation Frameworks with a Focus on NLP vs. LLM-as-a-Judge Metrics. In Proceedings of IEEE SIEDS; 2025.
Wang, Y.; Yuan, J.; Chuang, Y.N.; et al. DHP Benchmark: Are LLMs Good NLG Evaluators? In Findings of NAACL; 2025.
Crupi, G.; Tufano, R.; Velasco, A.; et al. On the Effectiveness of LLM-as-a-Judge for Code Generation and Summarization. IEEE Trans. Softw. Eng. 2025.
Hada, R.; Gumma, V.; de Wynter, A.; et al. Are Large Language Model-Based Evaluators the Solution to Scaling Up Multilingual Evaluation? In Findings of EACL; 2024.
Li, J.; Sun, S.; Yuan, W.; et al. Generative Judge for Evaluating Alignment. In Proceedings of ICLR; 2024.
Siri, D.; Anuragini, S.; Babu, B.S.; et al. Investigating Benchmarking Techniques for Unveiling Large Language Model Performance. In AIP Conference Proceedings; 2025.
- Cover Image
-
- Downloads
- Published
- 2026-03-25
- Section
- Articles
- Categories
- License
-

This work is licensed under a Creative Commons Attribution 4.0 International License.

How to Cite
Most read articles by the same author(s)
- Dea Nabila, Arbi Haza Nasution, Yohei Murakami, Stefan Koos, Ahmet Emre Ergun, Modeling and Benchmarking GraphRAG for Indonesian Legal Question Answering , Artificial Intelligence and Language Models: Vol. 1 No. 1 (2026): Volume 1, Issue 1
Similar Articles
- Dea Nabila, Arbi Haza Nasution, Yohei Murakami, Stefan Koos, Ahmet Emre Ergun, Modeling and Benchmarking GraphRAG for Indonesian Legal Question Answering , Artificial Intelligence and Language Models: Vol. 1 No. 1 (2026): Volume 1, Issue 1
- M Dzaky Efendi, Salhazan Nasution, Mondheera Pituxcoosuvarn, Leveraging Large Language Models for Indonesian Retail Sales Probabilistic Forecasting , Artificial Intelligence and Language Models: Vol. 1 No. 1 (2026): Volume 1, Issue 1
- Muhamad Shadri, Anggi Hanafiah, Parthasarathy Velusamy, AI-Generated Image Detection Using Convolutional Neural Network (CNN) Algorithm , Artificial Intelligence and Language Models: Vol. 1 No. 1 (2026): Volume 1, Issue 1
- Torang Siregar, The Trend of Gamification in Mathematics Learning: A Problem-Based Instruction Approach with AI Integration , Artificial Intelligence and Language Models: Vol. 1 No. 1 (2026): Volume 1, Issue 1
You may also start an advanced similarity search for this article.